Post
The Agent Test Score
In this guest post, Flo's VP of Engineering Andrei Varanovich argues that the real challenge in AI agents isn't intelligence — it's engineering discipline. Drawing on Google's ML Test Score, he introduces an 'Agent Test Score' framework to help teams ship agents that don't just demo well, but hold up in production.
February 13, 2026

What a 2017 ML Rubric Reveals About Why AI Agents Fail — and It's Not the AI
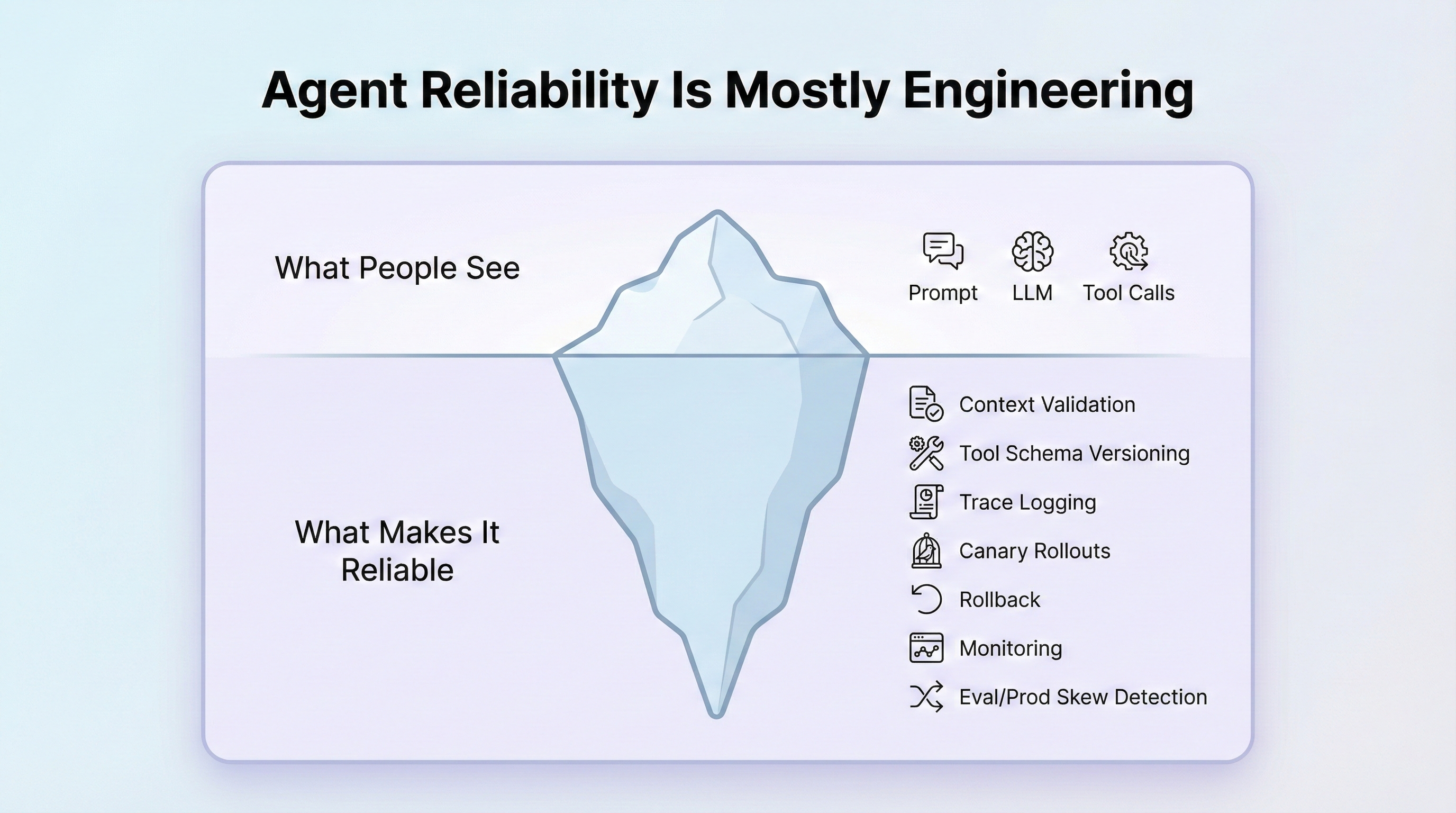
There is a dangerous illusion in AI development today: the belief that a powerful model solves engineering problems. It doesn't. You can prompt a model in seconds, but you cannot "prompt" reliability into a distributed system. Teams rush to ship agents that look like products, only to find they have built fragile demos. The retrieval step returns noise; a tool API changes silently; the agent loops indefinitely because nothing logged its first mistake. They aren't building software; they are building technical debt.
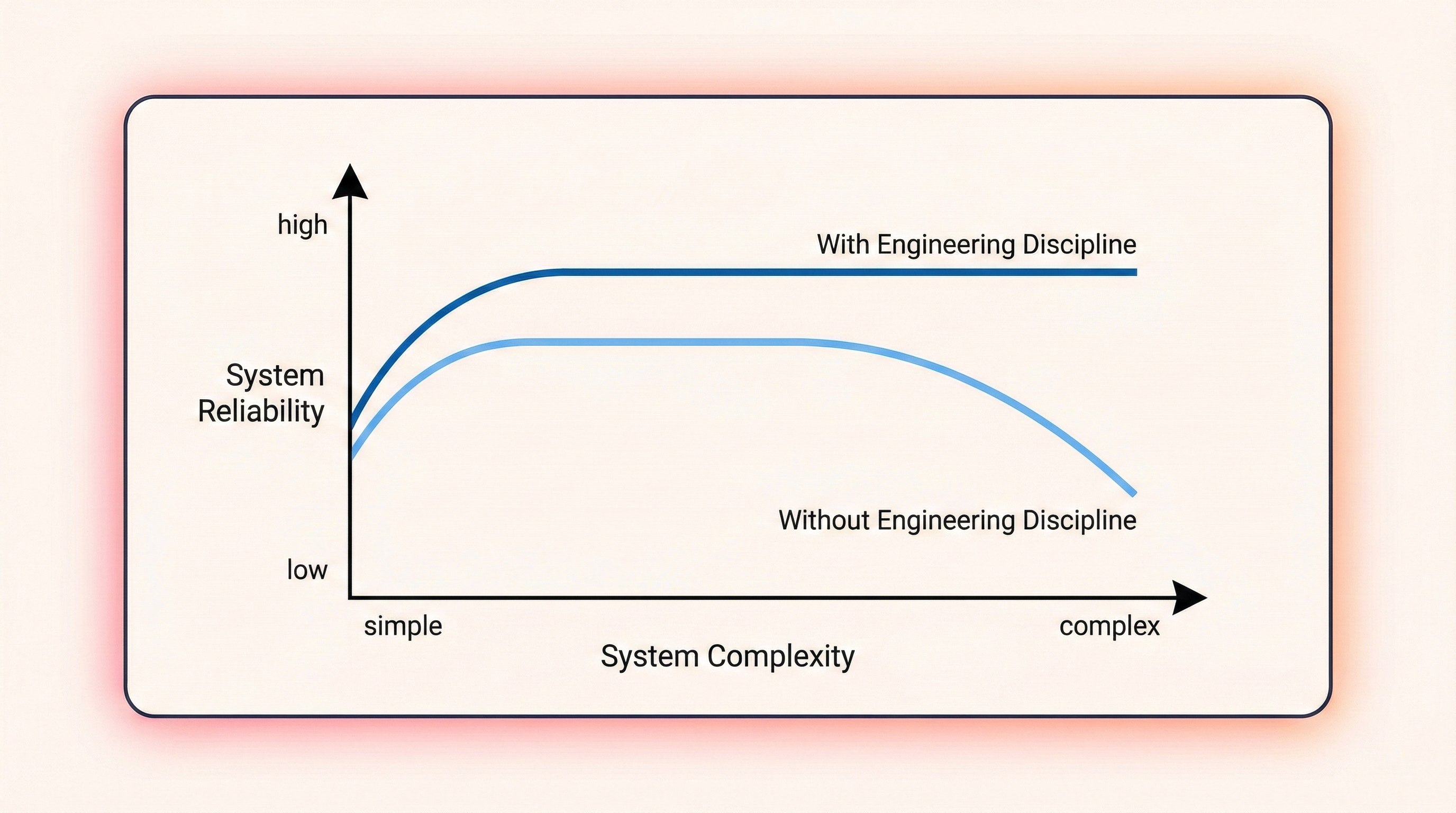
I have seen this pattern before — not with agents, but with ML teams. When I started building ML organizations, I grounded them in a single principle: machine learning is an engineering discipline. Zinkevich's Rules of Machine Learning articulated exactly what that meant in practice — start simple, measure everything, earn your complexity. The rules gave us a philosophy, but I needed a metric: something concrete to report on how an organization was doing, where the gaps were, what to invest in next. The ML Test Score gave me that metric. Twenty-eight tests, four categories, a single number that made invisible debt visible. I used it to benchmark teams, prioritize infrastructure work, and hold the line against shipping systems that passed a demo but would fail in production. Everything in this post comes from that experience — the conviction that the same discipline applies to agents, and that teams who skip it will pay the same price.
The recent OpenClaw saga made this visible at scale. The project — an open-source agent giving Claude persistent memory, tool access, and always-on autonomy — leapt from obscurity to over 100,000 GitHub stars in days. Then security researchers found hundreds of exposed instances leaking API keys, OAuth tokens, and chat histories to the open internet. Users had handed an autonomous agent the keys to their digital lives — no monitoring, no access controls, no rollback. Heather Adkins, VP of Security Engineering at Google, posted two words of advice: "Don't run."
These failures are not new. Their consequences are.
In 2017, Breck, Cai, Nielsen, Salib, and Sculley published The ML Test Score — 28 engineering tests drawn from dozens of production systems at Google, spanning data validation, model testing, infrastructure, and monitoring. Its companion, Zinkevich's Rules of Machine Learning, supplies the strategy: when to launch, what to build first, how to iterate. The ML Test Score supplies the checklist: what to test, how to verify it, how to know when you are done.
The principles that make traditional ML systems robust do not become obsolete when models move from predictions to actions. They become more critical. This post maps the ML Test Score onto the architecture of modern AI agents, showing how each practice adapts to context engineering, tool use, memory management, and real-world interaction.
We stand on the shoulders of giants. Teams that ignore classical ML wisdom will relearn it — one failed agent at a time.
"Teams that ignore classical ML wisdom will relearn it — one failed agent at a time."
Key Concepts: From ML to Agents
The table below maps core concepts from the ML Test Score and Zinkevich's Rules to their agentic counterparts. In each case, the concept matters more when models act rather than predict.
Data & Context
| ML Concept | Agentic Counterpart | Why It Matters More |
|---|---|---|
| Training data | Prompt context, retrieved documents, tool outputs | Training data is curated once. Agent context assembles at runtime from live sources — each request is a new dataset that can fail silently. |
| Feature engineering | Context engineering | Features are static transforms. Context must be curated, compressed, and scoped on every LLM call — a harder surface with tighter latency budgets. |
| Feature schema | Context validation rules | A malformed feature fails training. A malformed context produces a confident wrong answer the user may trust. |
| Feature cost/benefit | Context source cost/benefit | An unused ML feature wastes compute. Irrelevant context actively degrades LLM performance, inflates token cost, and triggers hallucination. |
Modeling & Evaluation
| ML Concept | Agentic Counterpart | Why It Matters More |
|---|---|---|
| Model selection | Model selection (still) | The tradeoff now includes latency per tool-use step, context window size, and instruction-following fidelity — not just accuracy. |
| Hyperparameter tuning | Temperature, top-k, reasoning effort, allowed tools, autonomy level, max steps, budget caps, context management strategy | A bad learning rate slows convergence. A bad agent configuration causes hallucinated tool calls, runaway loops, or autonomous actions without oversight. The parameter surface is wider and the failure mode is action, not prediction. |
| Offline evaluation | Eval suites, trajectory scoring, human judgment | Offline eval in ML tests one prediction. Agent eval must test multi-step trajectories where one bad step compounds into total failure. |
| Online metrics | Task completion rate, intervention rate, cost-per-task | ML optimizes a scalar. Agents must balance completion against safety, cost, latency, and human intervention — a multi-objective problem with no single number. |
Reliability & Drift
| ML Concept | Agentic Counterpart | Why It Matters More |
|---|---|---|
| Training/serving skew | Eval/production context skew | In ML, skew degrades accuracy. In agents, skew means the agent behaves differently in production than in testing — invisibly, until a user reports harm. |
| Model staleness | Stale retrieval index, outdated prompts, model drift | A stale ML model makes worse predictions. A stale agent acts on outdated facts: booking a cancelled flight, citing a repealed policy, calling a deprecated API. |
| Overfitting | Benchmark gaming, reward hacking, eval contamination | Overfitting an ML model hurts generalization. Agents go further: they game reward functions, peek at evaluation scaffolding, and search for benchmark answers online. The false confidence collapses on first contact with production. |
| Feature leakage | Context contamination | Leakage inflates ML metrics. Context contamination makes an agent appear capable when it merely echoes — subtler and harder to detect. |
| Feedback loops | Agent-generated data fed back into retrieval | ML feedback loops cause drift. Agent feedback loops are worse: an agent that writes documents later retrieved as ground truth entrenches its own errors. |
Infrastructure & Operations
| ML Concept | Agentic Counterpart | Why It Matters More |
|---|---|---|
| Pipeline monitoring | Trace logging, token-cost monitoring, latency tracking | ML pipelines fail in data. Agent pipelines fail in reasoning — without step-level tracing, you see the wrong answer but not which step produced it. |
| Serving infrastructure | Orchestration framework, tool APIs, memory stores | ML serving is stateless inference. Agent serving is stateful orchestration across LLM calls, tool APIs, and memory — more moving parts, more failure modes. |
| Canary deployment | Canary rollout of agent configurations | A bad ML model makes worse predictions on canary traffic. A bad agent configuration takes wrong actions on canary traffic: sending emails, modifying data, calling APIs. The blast radius is larger. |
| Rollback | Prompt and tool rollback (version-controlled) | Rolling back an ML model swaps a binary. Rolling back an agent means reverting prompts, tool schemas, retrieval indexes, and orchestration logic in concert. |
| Technical debt | Agent technical debt | ML debt accumulates in data pipelines and feature code. Agent debt adds prompt sprawl, tool proliferation, undocumented context dependencies, and untested tool interactions. |
I. Tests for Context and Data
ML systems differ from traditional software because behavior is learned from data, not written in code. Data needs testing as code does.
In agentic systems, the counterpart of training data is context: system prompts, retrieved documents, tool descriptions, user inputs, conversation history. Context shapes behavior at inference time. It deserves the same rigor.
Context 1: Capture context expectations in validation rules.
The original test asks teams to encode intuitions about input data and verify them automatically — a human's height falls between one and ten feet; English word frequencies follow a power-law distribution.
For agents, validate the context window before the model reasons over it. Is the retrieved document relevant, or did retrieval return noise? Is the tool output well-formed JSON, or an error string the agent will hallucinate over? Does the conversation exceed the window, truncating the system prompt?
These checks feel routine. They prevent disasters.
Context 2: Every piece of context earns its place.
The cost/benefit test warns against a kitchen-sink approach to features; each one carries cost. Zinkevich's Rule 21 reinforces this: the complexity you can support is proportional to the data you have to evaluate it.
Agentic systems face the same trap. Teams stuff the system prompt with every instruction, retrieve ten documents when two suffice, hand the agent fifteen tools when it needs four. Each addition widens the behavior space and makes evaluation harder. Worse, irrelevant context degrades LLM performance — unlike unused features in classical ML, which waste compute but do not confuse the model.
Audit context ruthlessly. If a prompt fragment, a retrieved document, or a tool description does not measurably improve task completion, cut it.
Context 3: No context source costs more than it returns.
Breck et al. ask teams to weigh inference latency, memory, upstream dependencies, and instability. For agents, every retrieval call, tool invocation, and sub-agent consultation adds latency, token cost, and a failure mode.
A retrieval step that takes two seconds and returns marginal documents may not justify the delay. A tool the agent invokes on five percent of tasks but that doubles latency on those tasks demands scrutiny. Measure each source's cost against its contribution.
Context 4: Every context source adheres to meta-level requirements.
The fourth data test asks whether features meet organizational standards beyond correctness: documentation, ownership, naming conventions, review processes. These meta-level requirements govern not what a feature computes but how it enters and persists in the pipeline.
For agents, the counterpart is governance over context sources. Every tool, retrieval index, and prompt fragment should have a documented owner, a defined contract for what it provides, and a review process for changes. Who maintains the CRM tool integration? What happens when the knowledge base schema changes — who is responsible for updating the retrieval pipeline? If the system prompt references a policy document, who ensures the reference stays current?
Without these contracts, context sources accumulate like features in an ungoverned ML pipeline: nobody remembers why they were added, nobody knows who owns them, and nobody tests them when dependencies shift. The result is the same debt the ML Test Score warns against — except that in an agent system, an orphaned context source does not just waste compute. It feeds stale or contradictory information into a system that acts on it.
Assign ownership. Document contracts. Review changes. Treat context sources as managed dependencies, not ambient inputs.
Context 5: The context pipeline respects privacy and data boundaries.
The privacy test concerns PII leakage during data export. For agents, the risk surface is larger. An agent may retrieve corporate documents, combine them with a personal query, and send the bundle to a third-party API. It may log conversations containing sensitive information. It may feed personal data to a tool that stores results externally.
Test that sensitive data does not leak across boundaries. Test that retrieval respects access controls. Test that logs are scrubbed. These are constraints to enforce from the start, not features to add later.
Context 6: New tools and context sources can be added quickly.
Breck et al. note that efficient teams move from a feature idea to production in one to two months. For agents, the measure is the time from "this agent needs CRM access" to the tool running live — documented, tested, evaluated.
If adding a tool takes weeks, your agent stagnates. Build a tool-integration framework that makes new capabilities cheap to add and simple to test. This is infrastructure work that pays compound interest.
Context 7: All context preparation code is tested.
Feature-creation code looks simple enough to skip testing, but bugs in it are nearly impossible to detect downstream.
The same holds for code that builds an agent's context: retrieval logic, prompt assembly, tool-output parsing, conversation truncation. A bug in your chunking strategy can split a critical paragraph across two chunks, making it unretrievable. A bug in prompt assembly can place the user's query before the system instructions, inverting the agent's priorities.
Unit test this code. It is load-bearing.
II. Tests for Agent Development
The second test category covers model development: code review, metric correlation, hyperparameter tuning, staleness, simplicity, sliced evaluation, fairness. For agents, this maps to prompts, tool configurations, orchestration logic, and evaluation.
Agent 1: Version-control and review system prompts, tool schemas, and orchestration logic.
Iterating on a system prompt in a playground and deploying from a notebook is tempting. Resist it. When an agent misbehaves in production, you need the exact prompt, tool configuration, and model version that produced the behavior. You need to diff it against last week's. You need to reproduce it.
Zinkevich's Rule 4 — keep the first model simple and get the infrastructure right — applies with force. Version control and code review are infrastructure. Get them right before you build the agent.
Agent 2: Verify that eval suite scores correlate with real-world task success.
This is one of the most important tests, and the most commonly violated. Teams build eval suites of curated test cases, tune their agents to score well, and discover that eval performance does not predict production performance. You can read more about this on Alex's blog Alignment Gap: Why "Smart" Agents Fail in Production.
The causes are familiar: the eval distribution does not match production; the eval tasks are too clean; the metrics measure the wrong thing. A correct answer in the eval may not be a useful answer in practice.
Invest early in measuring correlation between offline evals and online metrics — task completion, user satisfaction, intervention rate. If the correlation is weak, fix the evals before tuning the agent.
Agent 3: Tune all configuration parameters deliberately.
In classical ML, hyperparameters include learning rates, regularization coefficients, and layer sizes. For agents, the counterparts are temperature and sampling parameters, the number of retrieved documents, the maximum tool-use steps, retry thresholds, and context-window allocation among system prompt, history, and retrieved content.
Most teams set these once and never revisit them. The paper found that systematic search often uncovered hidden reliability issues. A temperature of 0.7 may work for creative tasks but cause erratic tool use. A top-k of 10 may flood the context with noise. Tune deliberately.
Agent 4: Know the impact of stale context.
The staleness test asks what happens when a model has not been retrained recently. For agents, staleness takes several forms: the retrieval index may be days old; the system prompt may reference changed policies; tool descriptions may not match the current API.
Measure the impact. If your knowledge base was last indexed a week ago, how does accuracy degrade? If the underlying LLM updates, how do your prompts hold up? Zinkevich's Rule 8 — know the freshness requirements of your system — remains essential.
Agent 5: Prove that a simpler agent is not better.
The paper recommends testing against a simple baseline. Does your multi-step system with tool use and retrieval outperform a single well-crafted prompt? Does your multi-agent architecture beat one agent with a good system prompt?
Sometimes the answer is no. When it is, the complex system is pure debt. Maintain the baseline. Test against it. Earn your complexity.
Agent 6: Evaluate quality across important task slices.
Global metrics hide local failures. An agent may complete ninety percent of tasks overall yet fail on every task involving a specific tool, language, domain, or intent. The paper warns that global summaries mask fine-grained problems.
Slice evaluations by task type, tool-usage pattern, conversation length, user segment, error category. The failures you find in slices are the failures your users already know about.
Agent 7: Test for fairness, bias, and harmful outputs.
Biases in training data shape system behavior invisibly. For agents, the surface is broader: biased retrieval, biased tool behavior, biased prompting.
Examine inputs for correlation with protected categories. Slice outputs by user group. Do not assume your system is fair because the inputs look like raw data.
III. Tests for Agent Infrastructure
The infrastructure tests cover reproducibility, unit testing, integration testing, pre-serving validation, debuggability, canary deployment, and rollback. They translate to agentic systems with little modification.
Infra 1: Make agent behavior reproducible given the same inputs.
Deterministic behavior simplifies debugging. Feed the same query, the same documents, the same tool responses — you should get the same output. In practice, non-determinism enters through sampling randomness, non-deterministic retrieval, time-varying tool responses, and model-provider updates.
Where you cannot eliminate non-determinism, log everything: the full context, the model version, the sampling parameters, the tool responses. Reproducibility after the fact is the next best thing.
Infra 2: Unit-test the code that defines the agent.
The second infrastructure test asks whether model specification code — feature transforms, loss functions, custom training logic — has unit tests. Breck et al. found that teams often treat this code as configuration rather than software, skipping tests because the code "just wires things together."
Agent-defining code carries the same risk. Prompt templates that interpolate variables can silently truncate or misequote. Tool-call parsers that expect JSON can break on unexpected whitespace or nested structures. Output validators that check for required fields can pass malformed responses when a field exists but contains garbage. Retry handlers that catch exceptions can mask permanent failures as transient ones.
Each of these is a small function. Each looks too simple to fail. Each, when it does fail, corrupts every downstream step — and the corruption surfaces as a mysterious agent behavior, not as a stack trace.
Unit test prompt assembly: verify that variables interpolate correctly, that the system prompt survives truncation logic, that tool descriptions render as expected. Unit test tool-call parsing: feed it malformed JSON, partial responses, error strings. Unit test output validation: confirm it rejects what it should reject. These tests are cheap to write and expensive to skip.
Infra 3: Integration-test the full agent pipeline.
Integration testing had the lowest adoption of any test among the 36 Google teams surveyed. The reason: training was an ad hoc collection of scripts and manual steps.
Agentic systems suffer the same disease. Retrieval lives in one codebase; the prompt template sits in a config file; tool implementations scatter across services; orchestration logic lives in a notebook. Nobody runs the full pipeline end to end in a test.
Build an automated test that exercises every stage: query → retrieval → context assembly → LLM call → tool execution → response. Run it on every commit. The paper found that teams with a framework making this easy scored far higher. Invest in the framework.
Infra 4: Validate agent output quality before serving.
In ML, this means running the trained model against a validation set before promotion. For agents, this means running your configuration — the new system prompt, the updated index, the new tool — against your eval suite before deploying.
Test for slow degradation across versions and sudden drops from a single change. The paper recommends both absolute thresholds and relative thresholds. Apply both.
Infra 5: Make every step of an agent's reasoning traceable.
When someone finds bizarre behavior, how hard is it to learn why? For agents: can you see the retrieved documents, the assembled prompt, the raw model output, the tool calls, the tool responses, and the final answer — all for one user request?
If you cannot, you will debug by guessing. Build observability before you need it.
Infra 6: Canary agent changes before full rollout.
The infrastructure tests highlight mismatches between model artifacts and serving infrastructure. For agents, the counterpart is a mismatch between a new prompt and the tools it references, or between a new tool schema and the code that parses its output.
Canary new configurations on a small fraction of traffic. Monitor for failures. Increase gradually. Teams with a framework that made canary deployment easy did it regularly. Teams without one did it once and never again.
Infra 7: Roll back agent configurations quickly and safely.
When a new configuration fails, how fast can you revert? If the answer involves reconstructing the previous prompt, redeploying the index, and restarting the service, you lack a rollback capability.
Version your configurations. Automate rollback. Practice it when nothing is on fire. The paper counsels that operators should rehearse emergency procedures in calm conditions.
IV. Tests for Monitoring
The final category addresses a simple question: does your system still work? Not at launch — now. For agents, where behavior depends on dynamic context from external sources, continuous monitoring matters even more.
Monitor 1: Alert when dependencies change.
An agent depends on a web of external systems: the LLM provider, the embedding model, the vector store, the tool APIs, the data sources behind retrieval. Any can change without notice — an API provider alters a response schema, the LLM provider updates the model, the vector store re-indexes with a new chunking strategy.
Subscribe to changelogs. Monitor schema changes. Alert when a tool's response distribution shifts. The paper warns that upstream changes can alter behavior without producing obviously wrong outputs.
Monitor 2: Verify that context invariants hold in production.
The second monitoring test asks whether data invariants that were held during training continue to hold during serving. A feature that was never null in training starts arriving null in production; a categorical variable gains an unexpected value; a distribution shifts beyond historical bounds.
For agents, context invariants are the runtime counterpart of the validation rules defined in Context 1. The difference: Context 1 enforces invariants at build time and in eval; Monitor 2 enforces them continuously on live traffic. A retrieval index that always returned English documents during evaluation may start returning mixed-language results after a re-index. A tool that returned structured JSON during testing may begin appending warning messages to its output. A system prompt that fit comfortably within the context window may overflow once production conversations grow longer than eval conversations anticipated.
Monitor these invariants on every request — or on a sampled fraction if volume demands it. Log violations. Alert when violation rates cross a threshold. The distinction between Context 1 and Monitor 2 is the distinction between testing your assumptions and verifying that they still hold.
Monitor 3: Detect eval/production context skew.
Training/serving skew ranks among the most damaging and least tested failures in ML. For agents, the counterpart is eval/production skew: the context your agent sees during evaluation differs from production context.
Common sources: eval uses curated documents, production uses live retrieval; eval uses stable tool mocks, production tools are flaky; eval uses short conversations, production conversations run long and messy; eval pins a model version, production calls "latest."
Log production contexts. Compare their distributions to eval contexts. Alert when they diverge.
Monitor 4: Ensure the agent's knowledge and tools are not stale.
Monitor the age of your retrieval index, the freshness of cached API responses, and the version of the underlying LLM. Set thresholds. Alert when exceeded.
Monitor 5 & 6: Detect degenerate outputs and computational regression.
The fifth monitoring test checks numerical stability: NaN values, infinite losses, gradients that explode or vanish. The sixth checks whether computational performance — training time, serving latency, throughput — has regressed. In classical ML, these are distinct concerns. For agents, they collapse into a single question: is the agent producing well-formed outputs at acceptable cost?
Degenerate outputs are the agentic counterpart of numerical instability. An agent that enters an infinite tool-call loop, returns empty responses, emits malformed JSON that downstream systems cannot parse, or repeats the same action without progress — each is a failure mode analogous to a NaN propagating through a neural network. The system has not crashed, but it has stopped producing useful work. Monitor for these patterns: loop detection on repeated tool calls, length bounds on responses, schema validation on structured outputs, and timeout enforcement on multi-step reasoning.
Computational regression maps directly. An agent's latency, token consumption, and cost-per-task can degrade silently as prompts grow, retrieval indexes expand, or model providers update their infrastructure. A change that adds fifty tokens to the system prompt may be invisible in eval but compound across thousands of production requests into measurable cost and latency increases. Track these metrics per request and in aggregate. Set baselines. Alert when they drift.
The two tests share an operational principle: monitor not just whether the agent gives the right answer, but whether it gives any well-formed answer within acceptable resource bounds.
Monitor 7: Detect performance regression on live traffic.
The paper offers three strategies for monitoring quality without ground truth: measure statistical bias in predictions, use tasks where labels arrive immediately, and have humans annotate production data periodically.
For agents: monitor tool-use failure rates and refusal rates as signals that need no ground truth; use tasks with verifiable outcomes — code agents where tests run, data agents where answers can be checked; and sample production conversations for human review. Set thresholds. Alert on both sudden drops and slow degradation.
Computing an Agent Test Score
The scoring system is simple. Half a point for running a test manually with documented results. A full point for automating it. Sum per category. Take the minimum across all four — a system is only as reliable as its weakest area.
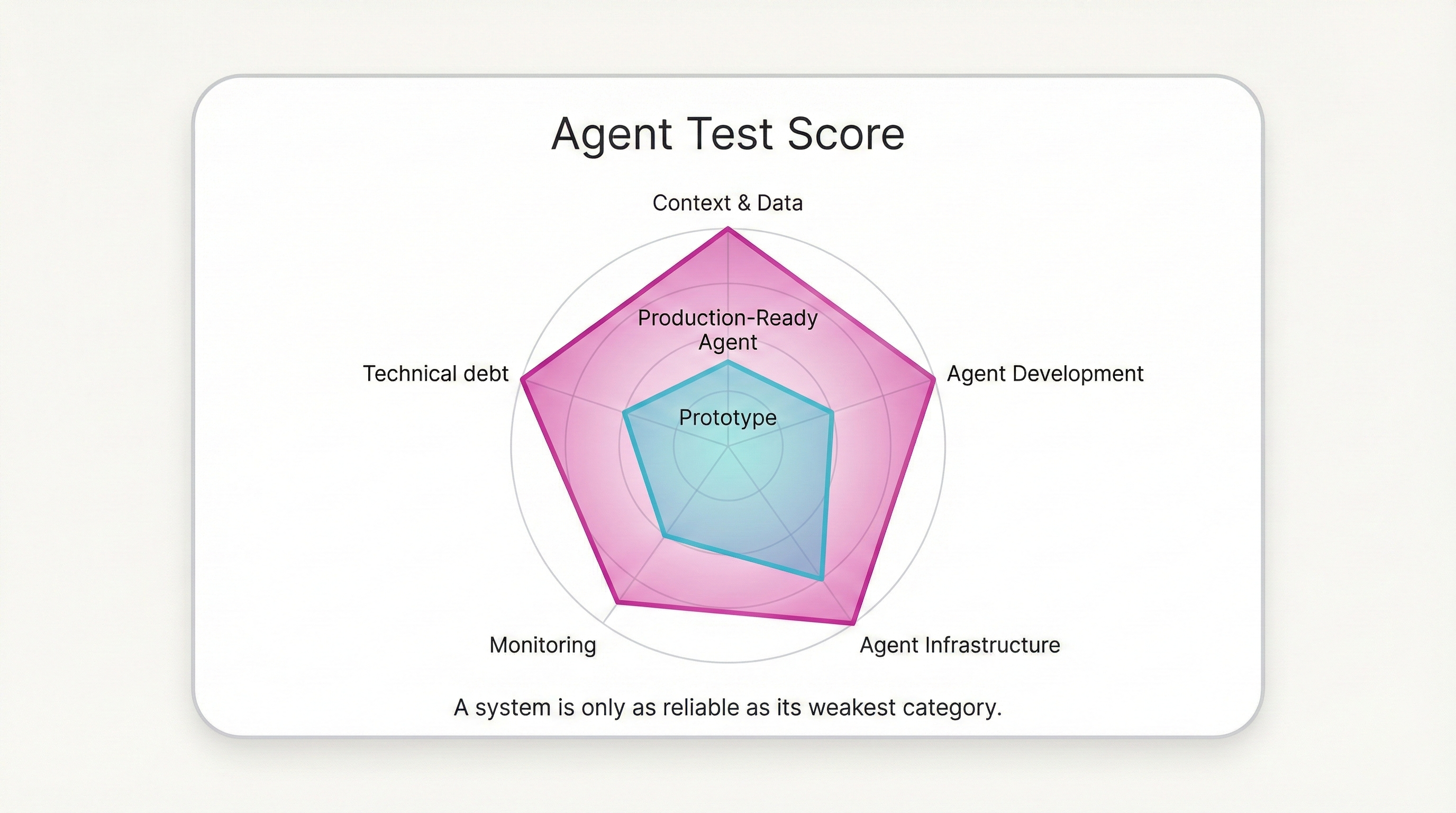
| Score | Meaning |
|---|---|
| 0 | A research prototype, not a production system. |
| (0, 1] | Not untested, but serious gaps remain. |
| (1, 2] | A first pass at production readiness. More investment needed. |
| (2, 3] | Reasonably tested. Automate what remains manual. |
| (3, 5] | Strong automated testing and monitoring. Fit for mission-critical agents. |
| > 5 | Exceptional. You have earned the right to build complex multi-agent systems. |
Conclusion
The ML Test Score paper ends with a section on culture change. The authors built their rubric not to find problems but to give teams a number to improve — a way to make invisible debt visible.
Agentic AI needs the same shift. Today, most agent development resembles early ML engineering: ad hoc scripts, manual evaluation, no integration tests, no monitoring, no rollback.
The fix is not new. Define your tests. Automate them. Monitor without pause. Score yourself honestly. Improve the weakest category first.
Zinkevich gives the philosophy — start simple, measure everything, iterate with care, earn your complexity. The ML Test Score gives the checklist. Together, they offer a road map for agents that do not just demo well but work reliably, day after day, at scale.
The technology is new. Engineering is not. Build on what works.
Related Work
Several works address the problem of engineering discipline for AI agents. This section surveys the five most relevant, noting where each connects to the present post and where it differs.
Sculley et al., "Hidden Technical Debt in Machine Learning Systems" (NIPS 2015) — Paper
Sculley and colleagues identified ML-specific sources of technical debt: boundary erosion, entanglement, hidden feedback loops, undeclared consumers, data dependencies. They argued that ML systems accumulate maintenance costs in ways traditional software does not. The ML Test Score responded directly — if Sculley diagnosed the disease, Breck et al. wrote the treatment protocol. This post extends both into the agentic era. The debt categories Sculley identified reappear in agent systems with amplified consequences: agents act on their errors rather than merely reporting them. Where Sculley diagnoses and the ML Test Score prescribes, this post translates the prescription into the specific language of prompts, tools, context windows, and orchestration.
Anthropic, "Building Effective Agents" (December 2024) — Blog post
Anthropic's guide draws on work with dozens of teams shipping LLM agents and arrives at a conclusion Zinkevich would recognize: start simple, add complexity only when warranted. The post introduces a useful taxonomy — 'workflows' (predefined orchestration) versus 'agents' (model-directed) — and recommends composable patterns over heavyweight frameworks. Its advice is architectural: what to build. This post addresses a different question: how to know whether what you built works. The ML Test Score provides the testing and monitoring discipline that sits beneath any architecture. A team can follow Anthropic's patterns and still fail without integration tests, canary deployment, or regression monitoring. The two complement each other; Anthropic tells you how to design the system, this post tells you how to verify it.
Anthropic Engineering, "Effective Context Engineering for AI Agents" (2025) — Blog post
This post formalizes the central metaphor of the present work: context engineering succeeds feature engineering. Anthropic defines 'context engineering' as the set of strategies for curating optimal tokens during inference and documents the phenomenon of 'context rot' — degrading model performance as context grows. The connection to the ML Test Score is direct: tests Data 1 through Data 7 (feature validation, cost/benefit analysis, schema enforcement) map onto context engineering with little modification. Where Anthropic offers strategies — write, select, compress, isolate — this post offers tests: how do you verify that your context engineering works, how do you catch regressions, how do you score overall readiness?
ZenML, "What 1,200 Production Deployments Reveal About LLMOps in 2025" — Blog post
The empirical evidence. Drawing on data from 1,200 production LLM deployments, the ZenML team reports that context engineering has become one of the clearest dividing lines between teams that ship reliable systems and teams that do not. They document the maturation from informal 'vibe checks' to sophisticated evaluation pipelines and confirm that simplifying architecture often delivers larger gains than adding complexity. This post shares the thesis but approaches it from a different direction: where ZenML reports patterns observed across deployments, the present work provides a prescriptive framework — a concrete checklist with a scoring rubric — that teams can apply to their own systems. ZenML's data validates the approach; the ML Test Score mapping operationalizes it.
Google Developers, "Architecting Efficient Context-Aware Multi-Agent Framework for Production" (December 2025) — Blog post
Google's engineering team — the same institution that produced both the ML Test Score and Zinkevich's Rules — applies systems-engineering discipline to agent context management. They argue that context engineering becomes systems engineering once you ask standard systems questions: what is the intermediate representation, where do we apply compaction, how do we make transformations observable? Their three design principles — separate storage from presentation, explicit transformations, scope by default — map directly to the ML Test Score's infrastructure tests. Where their post describes the architecture of Google's Agent Development Kit, this post provides the testing rubric that sits above any specific framework. A team can use ADK, LangGraph, or a custom orchestrator; the 28 tests apply regardless.
The ML Test Score (Breck et al., 2017), Zinkevich's Rules of Machine Learning, and Sculley et al.'s Hidden Technical Debt in Machine Learning Systems (NIPS 2015) are all freely available. Read them. Replace "feature" with "context," "model" with "agent," and "training data" with "prompt." Most of the rules still hold — and the ones that do not will teach you what is genuinely new.