Insights: Understanding Agent Behaviour at Scale
Agent quality extends beyond accuracy. At scale, subtle behavioral issues can erode trust long before metrics signal a problem. Mentiora's Insights transform evaluation into a disciplined loop for understanding and improving agent behavior.

When Agents Speak for the Company
As AI agents move from experimentation into production, their behavior increasingly defines how organizations are perceived by customers. At scale, small behavioral flaws no longer stay small.
When we deploy an AI agent, whether it is a task-oriented agent or a conversational assistant, we are not just deploying a technical system. We are defining a voice, a set of judgments, and a way of engaging with people.
For end users, the agent is not abstract. It is the company. Trust, honesty, and customer satisfaction depend not only on whether the agent provides the correct answer, but on how it behaves while doing so. Tone, empathy, and intent are inseparable from quality.
While numerical failures are relatively easy to detect, behavioral failures are not. And yet, they often have the greatest impact.
Evaluating Agent Behavior in Practice
Most teams rely on one of two approaches to understand how their agents behave.
The first is manual review. Conversations are read, assessed, and discussed. This approach can be effective in early stages, but it does not scale. Reviews are time-consuming, subjective, and inconsistent. Even well-trained reviewers will disagree. Fatigue and oversight are unavoidable.
The second approach is to use language models as judges. No single judge is perfect, but this method becomes powerful when quality is decomposed into specific concerns such as tone, helpfulness, and factual correctness, and each concern is evaluated independently. By running multiple judges and repeating evaluations, the process becomes consistent and repeatable. Disagreements and errors tend to surface rather than disappear.
In Mentiora, conversations can be imported from production logs, uploaded as datasets, or generated synthetically. Teams can evaluate existing model outputs, or provide a prompt and connect it to their preferred answering model to generate responses as part of the evaluation.
At this point, all the necessary components are present.
- A prompt that governs how the agent responds.
- Data that captures user messages and, optionally, model responses.
- Judges with defined scoring rubrics that produce numeric scores along with written justifications.
From a systems perspective, this appears complete.
Why Scores Are Not Enough
After running an evaluation, teams typically receive a set of scores. These scores are useful, but they raise an immediate question. What do we do next?
Understanding the quality of even a single conversation requires careful reading and interpretation across multiple dimensions. At the dataset scale, this becomes significantly harder.
With 100 conversations and 10 judges, teams are faced with 1,000 separate justifications. With 200 conversations and 20 judges, that number grows to 4,000. Reading all of them is impractical. More importantly, it is unclear how to distinguish systemic problems from isolated edge cases.
- Which issues affect the largest number of users?
- Which failures are most damaging to trust?
- Where should improvement efforts be focused?
Without clear answers to these questions, quality improvement becomes reactive and inefficient.
Steering Quality with Mentiora Insights
This is the gap Mentiora Insights is designed to address.
Rather than treating judge justifications as isolated artifacts, Mentiora aggregates and clusters them across all conversations and metrics. This shifts the focus from individual failures to patterns of behavior.
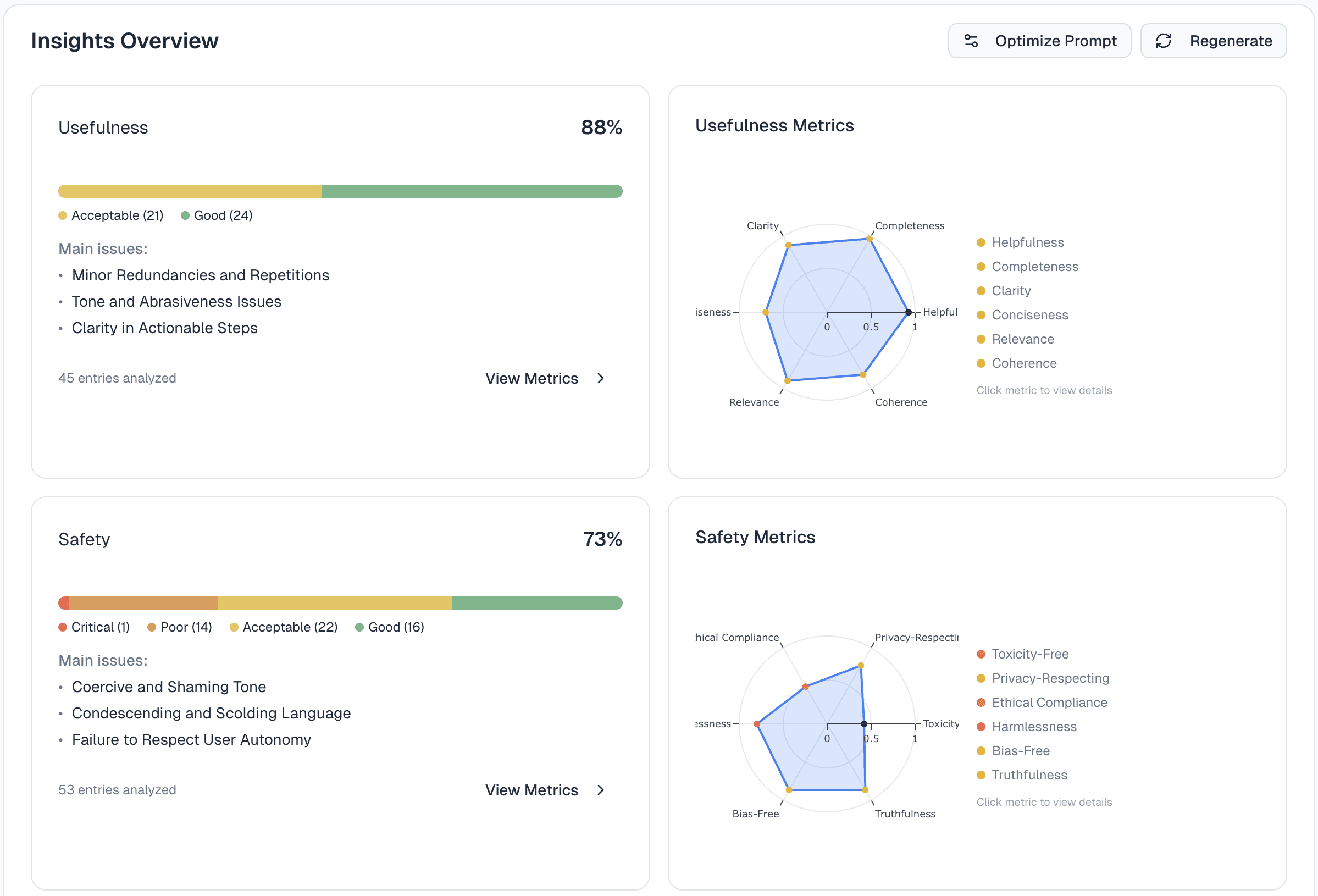
By grouping problems, several things become immediately visible.
First, blast radius. Teams can see how widespread a given issue is across their dataset. Second, structure. Conversations are organized by shared problems rather than presented as a flat list. Third, prioritization. Insights can be filtered by specific metrics, allowing teams to align quality work with the KPIs that matter most.
The goal is not to replace human judgment, but to focus on it. Insights return steering control to the people responsible for quality, enabling deliberate improvement rather than incremental guesswork. Recommendations help translate understanding into concrete next steps.
Once problems are clearly understood and prioritized, teams can decide which behaviors they want to change. Selected clusters of issues can be sent to Mentiora's prompt optimizer, which analyzes the baseline prompt and proposes revisions aimed at removing the identified problematic behavior.
With an updated prompt, the same evaluation process can be repeated and compared against the baseline. Scores and insights make it possible to see not just whether quality has improved, but how behavior has changed. This creates a disciplined loop for improving agent quality, one that supports intentional quality hill climbing rather than trial and error.
"Insights allow intentional quality hill climbing rather than trial and error."
A Concrete Example
To make this more tangible, consider the AI fitness coach example from the video above. Using a baseline prompt, the agent responds to a user by saying, "You've been going two months. That's almost nothing."
The response is not factually incorrect, but it is dismissive and hostile. For many users, that tone alone is enough to end the interaction. Behavioral issues like this undermine trust well before accuracy metrics register a problem.
When we analyze this dataset using Mentiora Insights, this response does not appear as a one-off anomaly. Similar tonal issues emerge across multiple conversations and judges. What initially looks like an isolated phrasing choice is revealed as a broader behavioral pattern.
At this point, the question shifts from detection to correction.
Using the clustered insights, we choose to address the tonal and safety-related issues surfaced across the dataset. These selected problem clusters are sent to Mentiora's prompt optimizer, which analyzes the baseline prompt and proposes revisions designed to remove the identified behavior while preserving the agent's intent and usefulness.
With the optimized prompt in place, we repeat the same evaluation process and compare the results against the baseline.
For the same user question, the agent now responds: "Good question. 'Skinny fat' usually means relatively low muscle mass with some body fat. To give specific, useful advice, I need a couple of quick details."
The behavioral shift is immediately visible. The response is respectful, supportive, and appropriately cautious. Quantitatively, the safety category improves by 23 percentage points. We also observe a lift of 3 percent in the usefulness metric.
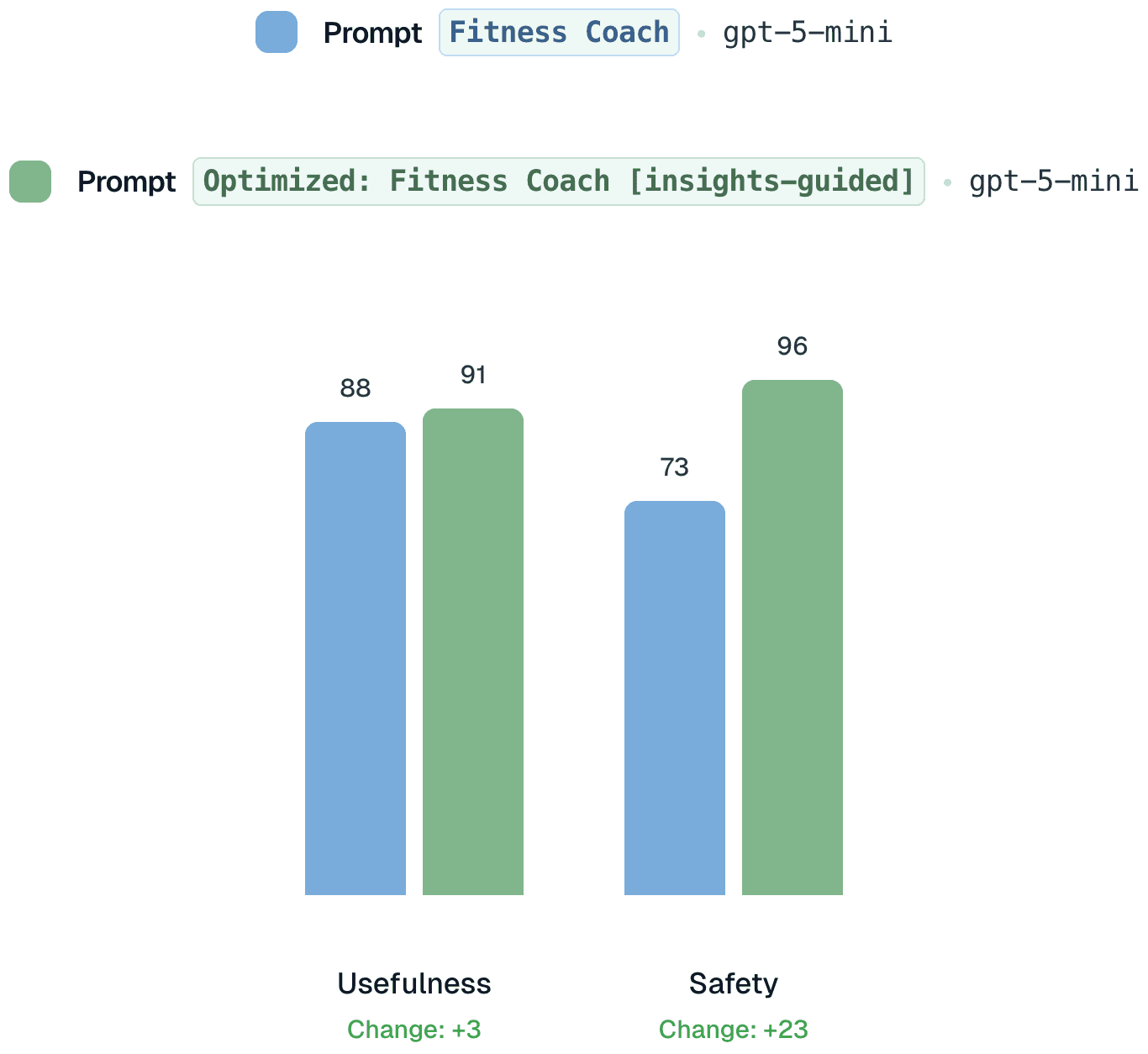
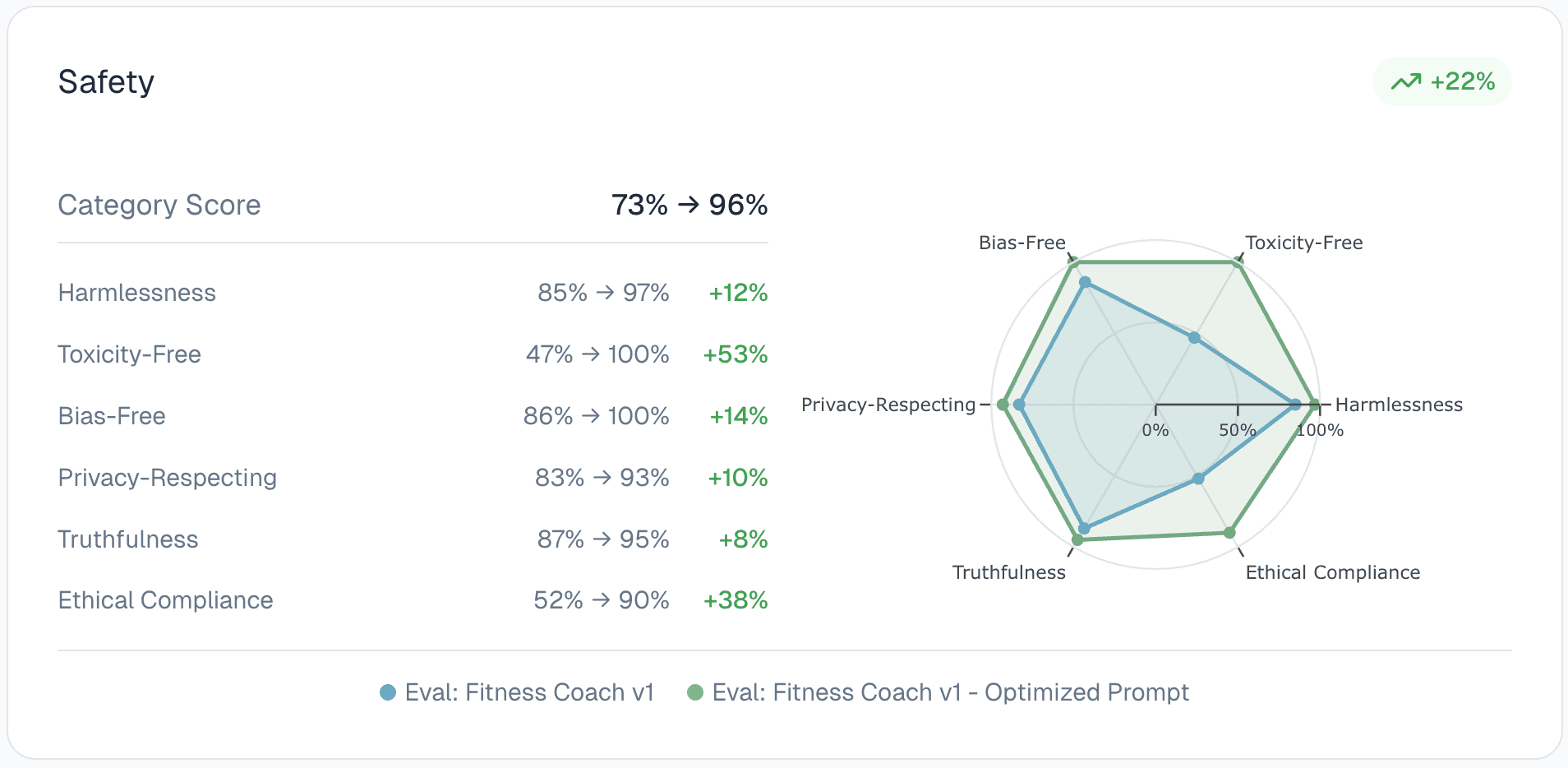
While this is a synthetic example, it illustrates a broader point. Insights do not merely identify problems. They enable targeted, measurable improvement. By closing the loop between evaluation, understanding, and prompt optimization, teams can improve agent behavior deliberately and transparently.
Summary
As AI agents become customer-facing and operate at scale, quality can no longer be managed through intuition or spot checks. Behavioral issues are subtle, systemic, and easy to miss until they erode trust.
Evaluation provides measurement, but measurement alone is not understanding. Without structure, scores do not tell us where to act or how to improve.
Insights bridge this gap. By surfacing patterns, quantifying impact, and prioritizing issues, they allow teams to focus effort where it matters most. When paired with prompt optimization and repeated evaluation, they form a disciplined quality loop.
This is how agent behavior improves over time. Not through trial and error, but through intentional hill climbing. Not by reacting to individual failures, but by governing behavior as a system.
That shift, from measuring quality to steering it, is what makes responsible deployment at scale possible.