Prompt Optimization Is Mission Critical
Prompting seems simple, but it steers how AI agents behave. In production, prompts aren't one-off crafts, but they're living system artifacts that need versioning and upkeep. Mentiora helps teams manage and optimize prompts, delivering measurable, repeatable performance gains at scale.

AI systems are advancing rapidly in capability. At the center of this progress sit large language models. These models may come from flagship providers or from the open-source ecosystem. Today, models from leading providers such as Google, OpenAI and Anthropic generally perform best across a wide range of benchmarks, while open-source alternatives like DeepSeek and Olmo are improving quickly and closing the gap in specific domains.
As models improve, expectations rise with them. We increasingly rely on AI systems for real work rather than experimentation alone. Reliability, consistency, and quality are now table stakes.
For API consumers of large language models, however, the number of levers available to influence model behavior remains limited.
I remember, early in 2022, those levers looked different. Developers could experiment freely with decoding strategies, inspect token-level probabilities, and fine-tune low-level generation behavior. Many of these controls still exist in some form, but the industry has steadily moved toward higher-level abstractions. Today, the most common controls involve reasoning settings, tool usage, and MCP servers a model may access while responding.
To appreciate the importance of prompt optimization, it helps to step back and understand what actually shapes a model's output.
Hierarchical Levers Shaping Model Output
At a high level, the output of a large language model is shaped by four types of factors.
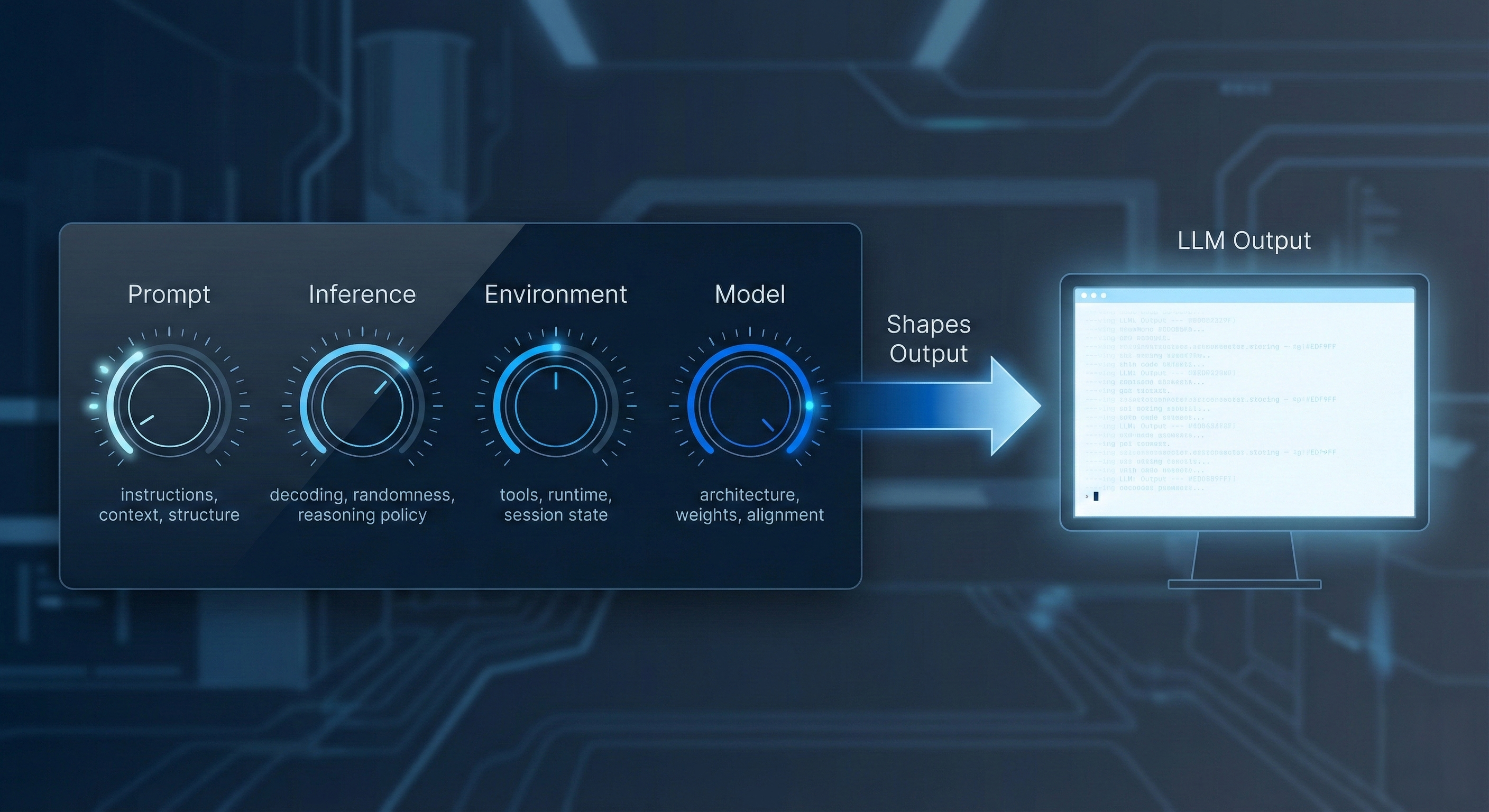
Prompt
The prompt encompasses everything the model conditions on at runtime. This includes system and developer instructions, user input, conversation history, retrieved context, and the structure used to represent all of this information.
Inference
Inference governs how the model's internal probability distribution is converted into concrete tokens. Decoding strategies, randomness, and reasoning policies live here, shaping variability and style without changing the model itself.
Environment
The environment includes the external systems that shape or mediate the interaction. Available tools, runtime infrastructure, routing and fallback behavior, and session state all fall into this category. These factors often operate invisibly, yet they can materially affect outputs.
Model
The model's architecture, size, trained weights, and alignment or preference tuning determine its capabilities, biases, and safety boundaries. Additional factors include presence of LORA adapters, tokenizing strategy, or using routers and MOE approaches.
Taken together, these layers form a clear hierarchy. The prompt is the most accessible and mutable layer. The model is the most centralized and expensive to change. This structure explains everyday behavior changes as well as broader shifts in system performance.
At the highest level, the relationship between these layers can be summarized as:
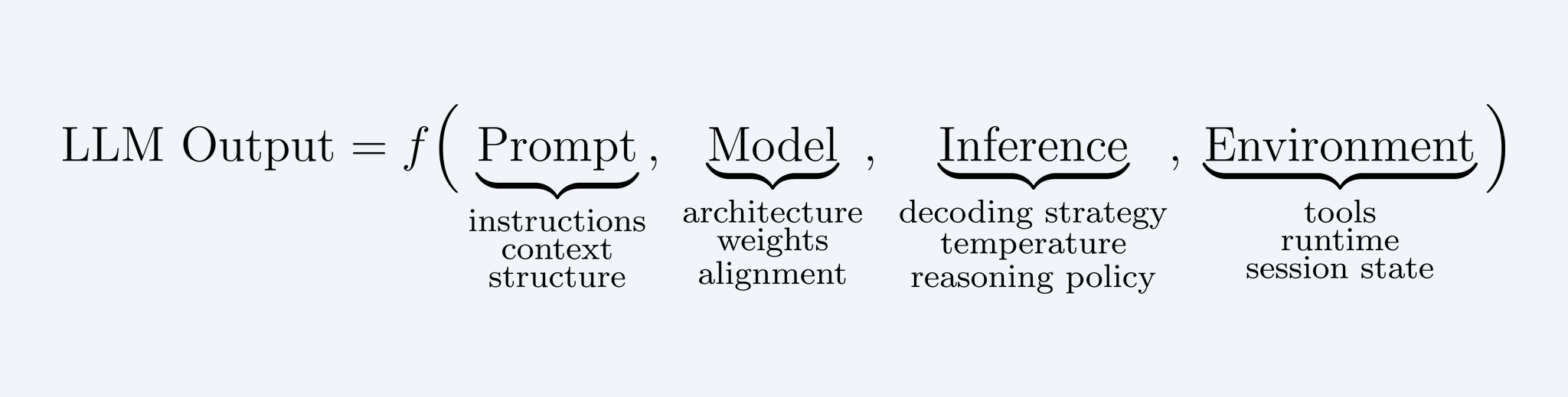
This framing is intentionally simple, but it remains useful as a mental model. It makes explicit where leverage exists and where it does not.
Who Controls What
The picture becomes sharper when we consider who can influence each layer, how costly it is to change, and how much technical knowledge is required.

A clear asymmetry emerges. End users typically have meaningful access to only one of the four levers: the prompt. The remaining layers are largely controlled by application developers, platform operators, and model providers, with cost and complexity increasing quickly as one moves down the stack.
This asymmetry has real consequences. When the only accessible lever is unmanaged, systems drift. Small prompt changes introduce regressions. Quality degrades silently. Teams compensate with intuition, ad hoc fixes, and manual reviews that do not scale.
This is the central reason prompt engineering, and more importantly prompt optimization, plays a critical role in modern AI systems. It is not far-fetched to say that Prompting is to AI models what programming is to traditional software.
"Prompting is to AI what programming is to traditional software"
There is also a humbling footnote. Despite how effective prompting has become, we still do not fully understand why it works as well as it does or how in-context learning unfolds at a mechanistic level. Active research continues, but a complete theory remains out of reach.
When Prompts Became Serious
One useful signal of where the field is heading is how model providers themselves treat prompts (e.g. prompting guides of OpenAI, Anthropic). Prompt migration guides now appear alongside model release notes. Prompts are no longer informal strings of text. They are artifacts that require maintenance, versioning, migrations, and care as models evolve.
Prompt structure has also changed materially. What began as simple role-based instructions has grown into carefully structured inputs. Modern prompts often contain explicit sections for scope constraints, output structure, verbosity, style, and long-context handling as XML-like tags. In practice, many prompts now resemble configuration files more than conversations.
As prompts grow, they also become fragile. Small edits can have outsized effects. Intent becomes harder to reason about. Behavior becomes harder to predict.
Without discipline, complexity accumulates quietly.
This shift reflects a growing recognition that prompts codify intent, constraints, and evaluation criteria in ways that directly shape system behavior.
Not only are prompts taken seriously by model providers and application developers, we are seeing an increased interest in prompt optimization also from the research community. Prompting has evolved from a manual "crafting" (trial and error setup) towards systematic, algorithmic optimization. Some of the major developments in this direction include: prompt programming (DSPy), TextGrad or automatic differentiation via text, Automated Prompt Optimization (APO) like GEPA.
It ain't real if it isn't measured
Optimization without evaluation amounts to guesswork. Evaluation remains the hardest part of the loop. It is expensive, domain-specific, and difficult to standardize.
This is where Mentiora focuses.
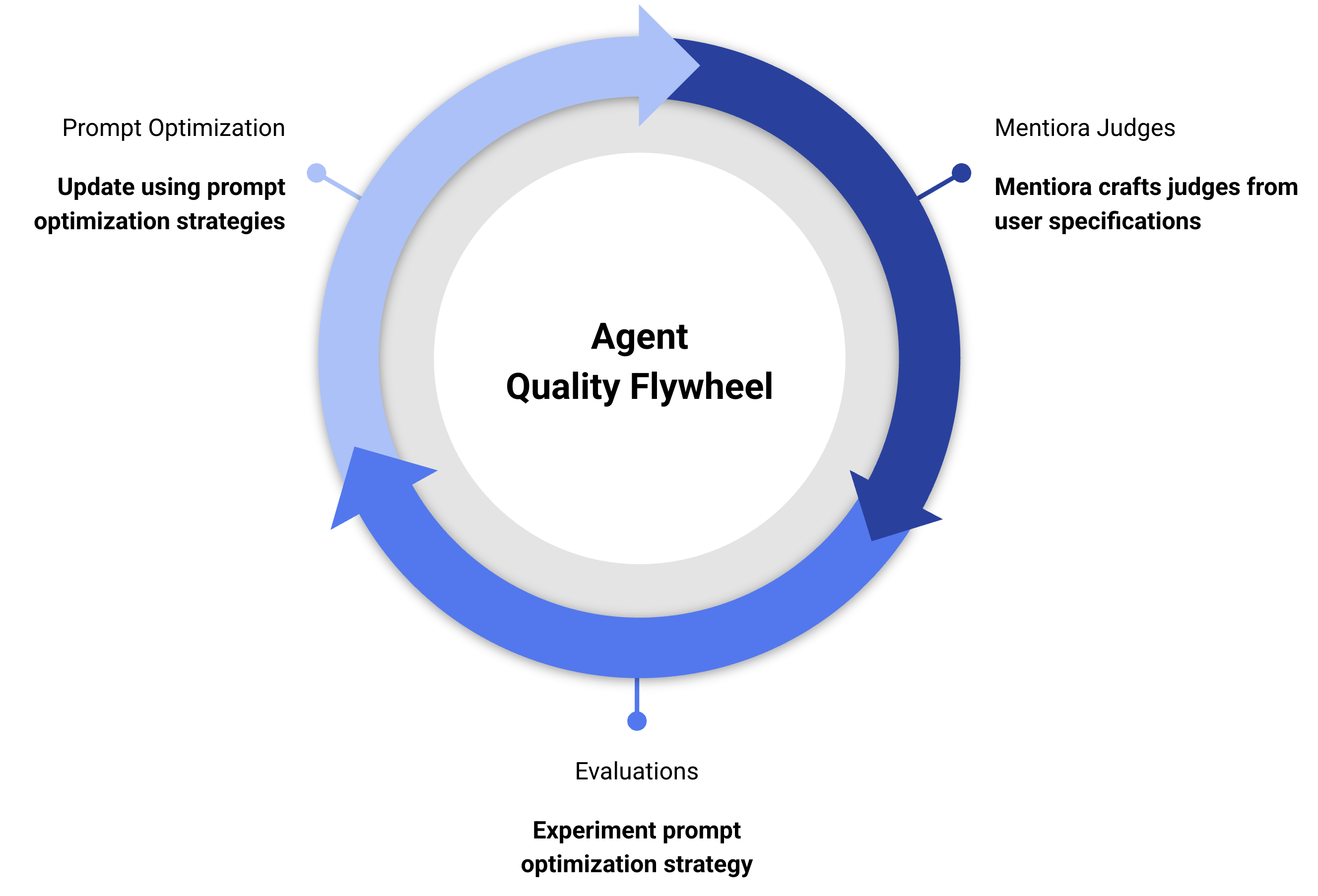
Mentiora Judges: You begin by specifying what you care about: evaluation categories (e.g. Helpfulness, Usefulness) and their metrics (e.g. Answer Relevance, Domain Handling) that matter for your specific domain like Medical, Legal, or E-Commerce. From those specifications, Mentiora automatically creates judges with rubrics. These judges are optimized evaluators designed to assess real outputs against real criteria without requiring teams to design evaluators from scratch.
Golden Data: How should we trust the automatically created judges? Bringing even a small set of 10-20 labelled examples helps calibrate Mentiora Judges to your use case. When the performance of these judges is optimized on your data, you're ready to use these judges for real evaluations.
Evaluation: The evaluation loop is now ready for action. Prompts are optimized using various strategies, the performance of agents and assistants is measured using Mentiora Judges. Their improvement, progress and performance is continuously measured using consistent evaluations. Quality improvement lives in a single, tight feedback loop.
This tight integration of Mentiora Judges and Evaluations leading to the quality improvement flywheel differentiates Mentiora. We believe quality is a first-class citizen in an AI system's lifecycle.
Here's an example of how all of this comes together.

Summary
Among the multiple ways of influencing a model's output, end users can use prompt optimization to their advantage. If prompts are the most accessible lever in modern AI systems, treating them casually is no longer an option.
Prompt optimization is mission critical. And the question is no longer whether prompts matter. It is how seriously we choose to treat them.
Mentiora's platform empowers you with judges, optimization strategies, and evaluations – all the tools you need to improve the prompt of your AI systems.